Running every inference on a cloud server introduces latency, bandwidth costs, and a single point of failure when the network drops. Running every inference on the edge device means you are limited to small models that sometimes lack the accuracy to handle ambiguous inputs. The hybrid approach combines both: the edge handles the easy cases instantly, the cloud handles the hard ones with a bigger model, and a retraining loop keeps the edge model improving over time. This lesson builds that complete system on hardware you already have from previous lessons. #EdgeCloud #TinyML #HybridAI
What We Are Building
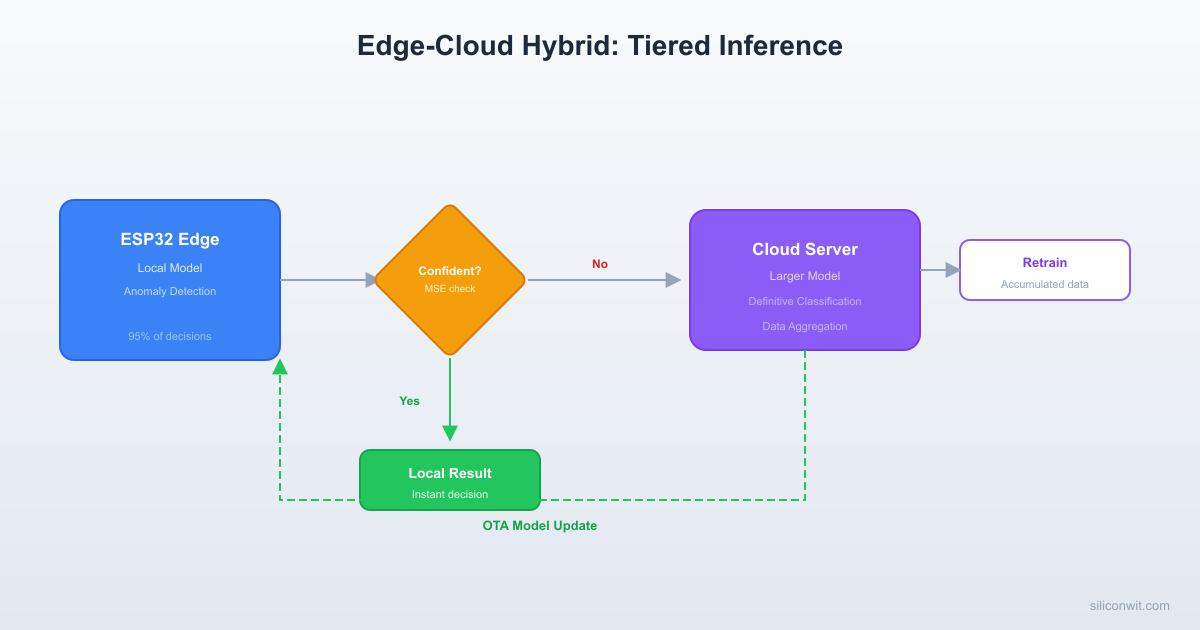
Edge-Cloud Hybrid Anomaly Detector
An ESP32 running the autoencoder from Lesson 7 (anomaly detection on motor vibration). When the reconstruction error falls clearly below or above the threshold, the ESP32 decides locally. When the error lands in an ambiguous zone near the threshold, the ESP32 sends the feature vector to a Python cloud server running a larger, more accurate model. The cloud returns a definitive classification. Periodically, the cloud retrains the edge model using accumulated escalated data, quantizes it, and pushes the updated .tflite to the ESP32 via HTTP OTA. An MQTT dashboard displays edge decisions, cloud escalations, model version, and device health.
System specifications:
Parameter
Value
Edge MCU
ESP32 DevKitC
Edge model
Autoencoder, ~12 KB int8 TFLite (from Lesson 7)
Cloud model
Larger autoencoder, ~200 KB float32 TensorFlow
Cloud server
Python FastAPI on a Linux host (PC, RPi 4, or VPS)
Escalation trigger
MSE in ambiguous zone between low_threshold and high_threshold
The system operates in three tiers. Each tier has a clear responsibility, and data flows upward only when the lower tier cannot handle the decision with sufficient confidence.
Tier 1: Edge Inference
The ESP32 collects a vibration window from the MPU6050 (100 samples at 200 Hz, 3 axes, yielding 300 values). It runs the small autoencoder and computes the mean squared error (MSE) between input and reconstruction. If the MSE is clearly below low_threshold, the input is classified as normal. If the MSE is clearly above high_threshold, the input is classified as anomalous. In both cases, the ESP32 acts immediately: toggling an LED, publishing an MQTT message, and moving to the next window. Approximately 95% of all inferences resolve at this tier.
Tier 2: Cloud Inference
When the MSE falls between low_threshold and high_threshold (the ambiguous zone), the ESP32 packages the 300-value feature vector as JSON and sends an HTTP POST to the cloud server. The server runs the same input through a larger autoencoder (wider layers, float32 precision) that is more accurate in the ambiguous region. The server returns a JSON response with the classification and confidence score. The ESP32 uses this result to make the final decision. This tier handles roughly 5% of inferences.
Tier 3: Cloud Retraining
The cloud server stores every escalated feature vector along with its final classification. Periodically (e.g., once per day, or after accumulating 500 new samples), a retraining script loads all accumulated data, retrains the edge autoencoder with the expanded dataset, quantizes the result to int8, and saves the new .tflite file to a directory served by HTTP. The next time the ESP32 checks for updates (on boot or on a timer), it downloads the new model, writes it to a dedicated flash partition, and reloads the TFLite Micro interpreter. Over time, the edge model’s ambiguous zone shrinks as it learns from the cases it previously could not handle.
Data Flow
The data flows through the system as follows. The ESP32 reads a vibration window from the MPU6050 over I2C. It runs the autoencoder and computes MSE. If the result is decisive, the ESP32 publishes the classification to MQTT topic edge-ai/device/{id}/inference and proceeds. If the result is ambiguous, the ESP32 posts the feature vector to http://{server}:8000/classify, receives the cloud classification, publishes both the edge MSE and cloud result to MQTT topic edge-ai/device/{id}/escalation, and proceeds. On a separate timer, the ESP32 sends an HTTP GET to http://{server}:8000/model/version to check for updates. If a new model version is available, it downloads the .tflite file, writes it to the model partition in flash, reinitializes the interpreter, and publishes the new model version to MQTT topic edge-ai/device/{id}/status.
Tiered Inference: When to Escalate
The core idea is to define a confidence zone around the anomaly threshold. Instead of a single threshold, you use two.
Zone
MSE Range
Decision
Actor
Normal
MSE < low_threshold
Normal (high confidence)
Edge
Ambiguous
low_threshold to high_threshold
Uncertain (escalate)
Cloud
Anomaly
MSE > high_threshold
Anomaly (high confidence)
Edge
You derive low_threshold and high_threshold from the training data distribution. If the mean training MSE is mu and the standard deviation is sigma, a reasonable starting point is:
low_threshold = mu + 2.0 * sigma
high_threshold = mu + 4.0 * sigma
This means anything within 2 sigma of the normal mean is definitely normal, anything beyond 4 sigma is definitely anomalous, and the zone between 2 and 4 sigma gets escalated. You can tune these multipliers based on your application’s tolerance for false positives vs false negatives.
ESP32 Tiered Decision Logic
The following code integrates into the inference loop from Lesson 7. After computing the MSE, instead of comparing against a single threshold, it routes through the three-zone logic.
tiered_inference.h
#ifndefTIERED_INFERENCE_H
#defineTIERED_INFERENCE_H
#include<stdbool.h>
typedefenum {
DECISION_NORMAL,
DECISION_ANOMALY,
DECISION_UNCERTAIN
} inference_decision_t;
typedefstruct {
float mse;
inference_decision_t decision;
bool escalated;
float cloud_confidence;
int cloud_classification; // 0=normal, 1=anomaly, -1=not escalated
} inference_result_t;
// Thresholds (set from training data statistics)
externfloat g_low_threshold;
externfloat g_high_threshold;
inference_decision_tclassify_mse(floatmse);
#endif
tiered_inference.c
#include"tiered_inference.h"
float g_low_threshold =0.015f; // mu + 2*sigma (example values)
float g_high_threshold =0.045f; // mu + 4*sigma (example values)
inference_decision_tclassify_mse(floatmse)
{
if (mse < g_low_threshold) {
return DECISION_NORMAL;
} elseif (mse > g_high_threshold) {
return DECISION_ANOMALY;
} else {
return DECISION_UNCERTAIN;
}
}
The main inference loop uses this function to decide whether to act locally or escalate.
Notice the fallback logic: if the cloud server is unreachable, the ESP32 picks the closer threshold rather than blocking. This ensures the system never stalls waiting for a network response.
Cloud Inference Server
The cloud server is a Python FastAPI application. It loads a larger autoencoder (trained on the same vibration data but with wider layers and float32 precision) and exposes two endpoints: /classify for inference and /model/version for OTA version checking.
Server Setup
Install the dependencies: pip install fastapi uvicorn tensorflow numpy
Train the larger cloud model (see the retraining section below) or use an expanded version of the Lesson 7 autoencoder
Place the saved model in a models/ directory
Run the server: uvicorn cloud_server:app --host 0.0.0.0 --port 8000
raiseHTTPException(status_code=404,detail="No edge model available")
returnModelVersionResponse(
version=EDGE_MODEL_VERSION,
filename="model.tflite",
size_bytes=tflite_path.stat().st_size
)
@app.get("/model/download")
asyncdefdownload_model():
from fastapi.responses import FileResponse
tflite_path =Path(EDGE_MODEL_DIR) /"model.tflite"
ifnot tflite_path.exists():
raiseHTTPException(status_code=404,detail="No edge model available")
returnFileResponse(
path=str(tflite_path),
media_type="application/octet-stream",
filename="model.tflite"
)
The server logs every escalated feature vector to a JSONL file. This file becomes the training data for the retraining pipeline. Each line contains the raw features, the edge MSE that triggered escalation, and the cloud model’s final classification.
ESP32 Cloud Escalation
When the edge model returns an uncertain MSE, the ESP32 needs to send the feature vector to the cloud and parse the response. This uses the ESP-IDF HTTP client library.
The key design choices here are the 5-second timeout (long enough for a Wi-Fi round trip, short enough to avoid blocking the inference loop) and the graceful degradation when the cloud is unreachable. The caller in inference_task handles the fallback to threshold-based classification.
OTA Model Updates
The most powerful aspect of a hybrid architecture is the ability to improve the edge model over time without physically touching the device. This section covers how to structure the ESP32 firmware so that the TFLite model is loaded from a flash partition rather than compiled into the binary, enabling updates without reflashing the entire firmware.
Partition Table
Add a custom partition for storing the model. Create a file called partitions.csv in your ESP-IDF project root.
# ESP-IDF Partition Table for OTA Model Updates
# Name, Type, SubType, Offset, Size, Flags
nvs, data, nvs, 0x9000, 0x6000,
phy_init, data, phy, 0xf000, 0x1000,
factory, app, factory, 0x10000, 0x1E0000,
model, data, fat, 0x1F0000, 0x10000,
The model partition is 64 KB, which is more than enough for a 12 KB quantized autoencoder with room to grow. Set the partition table in sdkconfig:
ESP_LOGI(TAG, "Loaded model v%lu (%lu bytes) from flash", *version, *model_size);
return ESP_OK;
}
uint32_tmodel_storage_get_version(void)
{
constesp_partition_t*part =get_model_partition();
if (part ==NULL) return0;
model_header_t header;
if (esp_partition_read(part, 0, &header, sizeof(header))!= ESP_OK) return0;
if (header.magic!= MODEL_MAGIC) return0;
returnheader.version;
}
OTA Download and Update on ESP32
The ESP32 periodically checks the cloud server for a new model version. If a newer version is available, it downloads the .tflite file and writes it to the model partition.
ESP_LOGI(TAG, "Model updated to v%d, interpreter reloaded", remote_version);
}
}
Reloading the TFLite Micro Interpreter
When a new model is written to flash, the interpreter must be reinitialized. The following function replaces the model pointer and rebuilds the interpreter.
// interpreter_reload.c (C++ file in practice, as TFLite Micro uses C++)
printf("Interpreter reloaded with new model (%u bytes)\n",
(unsigned)model_size);
}
On first boot, if no model is found in the flash partition, the firmware falls back to the compiled-in default model. After the first OTA update, subsequent boots load from flash.
Cloud Retraining Pipeline
The retraining script runs on the cloud server (manually or as a cron job). It reads all escalated feature vectors from the JSONL log, combines them with the original training data, retrains the edge autoencoder, quantizes it to int8, and saves the new .tflite file.
print(f"Escalation log archived to {archive_path}")
if __name__ =="__main__":
main()
After running this script, the new model.tflite is immediately available at the /model/download endpoint. The next time any ESP32 device checks for updates, it will download and deploy the improved model.
Retraining Workflow
Escalated feature vectors accumulate in data/escalations.jsonl as the ESP32 devices encounter ambiguous cases
Run python retrain_edge_model.py manually, or schedule it as a daily cron job
The script combines original training data with newly collected normal samples
After training, it quantizes the model to int8 and increments the version number
ESP32 devices detect the new version on their next check cycle (every 30 minutes) and download the update automatically
MQTT Dashboard Integration
The ESP32 publishes all decisions, escalations, and system health to MQTT topics. This integrates directly with the MQTT broker and Grafana dashboards covered in the IoT Systems course.
Topic Hierarchy
edge-ai/
device/
{device_id}/
inference # Every local decision
escalation # Cloud escalation events
status # Model version, uptime, health
ota # OTA update events
JSON Payloads
Each message uses a consistent JSON structure with a timestamp, making it straightforward to parse in Grafana or any MQTT subscriber.
If you completed the IoT Systems course, you can point Grafana at these MQTT topics (via an InfluxDB or TimescaleDB bridge) to visualize inference rates, escalation frequency, model version transitions, and device health over time. The SiliconWit.io dashboard also supports direct MQTT subscription for real-time monitoring.
Federated Learning Concepts
The retraining pipeline described above is centralized: raw feature vectors are sent to the cloud, and the cloud retrains the model. This works well for a small fleet, but it raises concerns at scale. Sending raw sensor data from hundreds of devices consumes bandwidth and may expose sensitive operational patterns. Federated learning offers an alternative.
What Federated Learning Is
In federated learning, the model is trained across multiple devices without sharing raw data. Instead of uploading feature vectors, each device computes a local model update (gradient or weight delta) using its own data. Only these compressed updates are sent to a central server, which aggregates them into a global model improvement. The updated model is then distributed back to all devices.
The key benefit is that raw data never leaves the device. The server only sees aggregated statistical summaries, not individual measurements.
How It Would Work for Edge AI
Consider a factory with 50 ESP32 vibration monitors on different machines. Each device accumulates local vibration data during normal operation. In a federated approach:
The server sends the current global model to all devices
Each device trains the model locally on its own vibration data for a few epochs
Each device computes the difference between its updated weights and the original weights (the “gradient” or “delta”)
Each device sends only this compressed delta (a few KB) to the server
The server averages the deltas from all participating devices (this is called FedAvg, the most common aggregation algorithm)
The server applies the averaged delta to the global model, producing an improved version
The process repeats from step 1
Gradient Aggregation vs Feature Summary
There are two broad strategies for what each device shares with the server.
Strategy
What is shared
Bandwidth
Privacy
Complexity
Gradient aggregation (FedAvg)
Weight deltas after local training
Low (model size, once per round)
High (no raw data)
Moderate
Feature summary
Statistical summaries (mean, variance, histogram of MSE values)
Very low
High
Low
Raw data upload (current approach)
Full feature vectors
High
Low
Low
For MCU-based systems, feature summary approaches are often more practical. Computing full backpropagation on an ESP32 is possible but slow. Sending a 64-byte statistical summary (mean and variance of each sensor channel, histogram of MSE distribution) is far cheaper than sending model gradients.
Privacy and Bandwidth Benefits
Privacy matters even in industrial settings. A factory’s vibration patterns can reveal production schedules, equipment utilization rates, and maintenance practices. Federated learning prevents this data from leaving the facility while still allowing cross-facility model improvement.
Bandwidth savings are significant at scale. Uploading 300 floats (1.2 KB) per escalation from 50 devices, with 10 escalations per hour, produces 14.4 MB of raw data per day. A federated round that shares only weight deltas (12 KB per device, once per day) produces 600 KB total.
Current State on MCUs
Full federated learning on MCUs is an active research area with practical limitations.
Available frameworks:
TensorFlow Federated (TFF) provides simulation tools but does not run on MCUs directly
Flower (flwr.ai) is a federated learning framework with experimental embedded support
Custom lightweight implementations are the most common approach for production MCU deployments
Limitations:
Backpropagation on ESP32 is feasible for small models but slow (minutes per epoch)
RAM constraints limit local batch sizes
Wi-Fi power consumption during communication rounds can be significant for battery-powered devices
Convergence requires many rounds, each requiring all devices to be online
Practical compromise for today: Use the centralized retraining pipeline (as built in this lesson) for small fleets. For larger deployments where privacy or bandwidth is a concern, implement a feature summary approach where each device periodically uploads compressed statistics rather than raw data. True gradient-based federated learning on MCUs will become more practical as frameworks mature and MCU capabilities increase.
Edge vs Hybrid vs Cloud Decision Framework
Choosing between pure edge, hybrid, or pure cloud inference depends on your application’s constraints. The following table summarizes the tradeoffs.
Factor
Pure Edge
Hybrid (this lesson)
Pure Cloud
Latency
Lowest (ms)
Low for easy cases, higher for escalations
Highest (network dependent)
Bandwidth
None (no network needed)
Low (only ambiguous cases)
High (every sample)
Privacy
Best (data stays on device)
Good (only ambiguous data leaves)
Worst (all data uploaded)
Model complexity
Limited by MCU resources
Small on edge, large on cloud
Unlimited
Accuracy
Limited by small model
Best of both (edge speed, cloud accuracy)
Highest (large model)
Offline operation
Full
Partial (degrades gracefully)
None
Update frequency
Requires OTA firmware update
Model-only OTA (simpler)
Instant (server-side)
Fleet management
Hard (each device independent)
Moderate (cloud coordinates)
Easy (single model)
Cost at scale
Low (no server)
Moderate (small server)
High (compute per inference)
Connectivity required
No
Intermittent
Always
When to Use Each Approach
Pure edge is the right choice when connectivity is unreliable or absent, latency requirements are strict (sub-millisecond), privacy is critical, or the classification task is simple enough that a small model handles it well.
Hybrid (the architecture in this lesson) is the right choice when most decisions are straightforward but a meaningful fraction are ambiguous, when you want the edge model to improve over time, when you need both fast response and high accuracy, or when the fleet is small to medium sized (up to a few hundred devices).
Pure cloud is the right choice when the model is too large or complex for any MCU, when connectivity is reliable and always available, when centralized logging and compliance require that all data pass through a server, or when the inference task changes frequently and deploying updates to edge devices is impractical.
Exercises
Tune the ambiguous zone. Modify the low_threshold and high_threshold values in tiered_inference.c. Set low_threshold = mu + 1*sigma and high_threshold = mu + 5*sigma (wider zone). Then set low_threshold = mu + 2.5*sigma and high_threshold = mu + 3.5*sigma (narrow zone). For each configuration, run the system for 10 minutes and record the escalation rate, edge accuracy, and total latency distribution. Which configuration gives the best balance between cloud usage and accuracy?
Add OTA threshold updates. The current OTA system only updates the .tflite model file. Extend it to also download and apply new low_threshold and high_threshold values from the server. Add a /model/thresholds endpoint to the FastAPI server that returns the threshold config JSON. Modify the ESP32 OTA task to fetch and apply these thresholds after each model update.
Implement exponential backoff for cloud failures. The current escalation code retries on the next uncertain inference if the cloud is unreachable. Implement an exponential backoff: after a cloud failure, wait 1 minute before trying again, then 2 minutes, then 4, up to a maximum of 30 minutes. Reset the backoff timer after a successful cloud response. Track and publish the backoff state via MQTT.
Build a feature summary reporter. Instead of sending raw feature vectors for escalation, implement a feature summary on the ESP32 that computes and sends: per-axis mean and variance (6 values), MSE histogram with 10 bins (10 values), peak frequency from a simple FFT (3 values, one per axis), and sample count. This 20-value summary replaces the 300-value feature vector. Modify the cloud server to accept and store these summaries. Compare bandwidth usage with the raw feature approach.
Multi-device fleet simulation. Run two or more ESP32 devices (or simulate multiple devices by changing DEVICE_ID and running sequential sessions). Each device should publish to its own MQTT subtopic. Modify the retraining script to aggregate escalation data from all devices. Verify that a model retrained on combined data from multiple devices improves performance for each individual device when deployed via OTA.
Summary
You built a complete edge-cloud hybrid system that combines the speed and reliability of on-device inference with the accuracy and adaptability of cloud computing. The ESP32 handles the vast majority of vibration classification decisions locally in milliseconds, escalates only the ambiguous cases to a FastAPI server running a larger model, and receives improved models via HTTP OTA as the cloud accumulates more training data. The MQTT telemetry layer provides visibility into every decision, escalation, and model update across the fleet. This architecture represents the practical middle ground that most production edge AI systems converge on: fast local inference for the common case, cloud backup for the hard cases, and a continuous improvement loop that makes the edge model smarter over time. The federated learning concepts introduced here point toward the next evolution, where model improvement happens without raw data ever leaving the device.
Comments