import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, f1_score
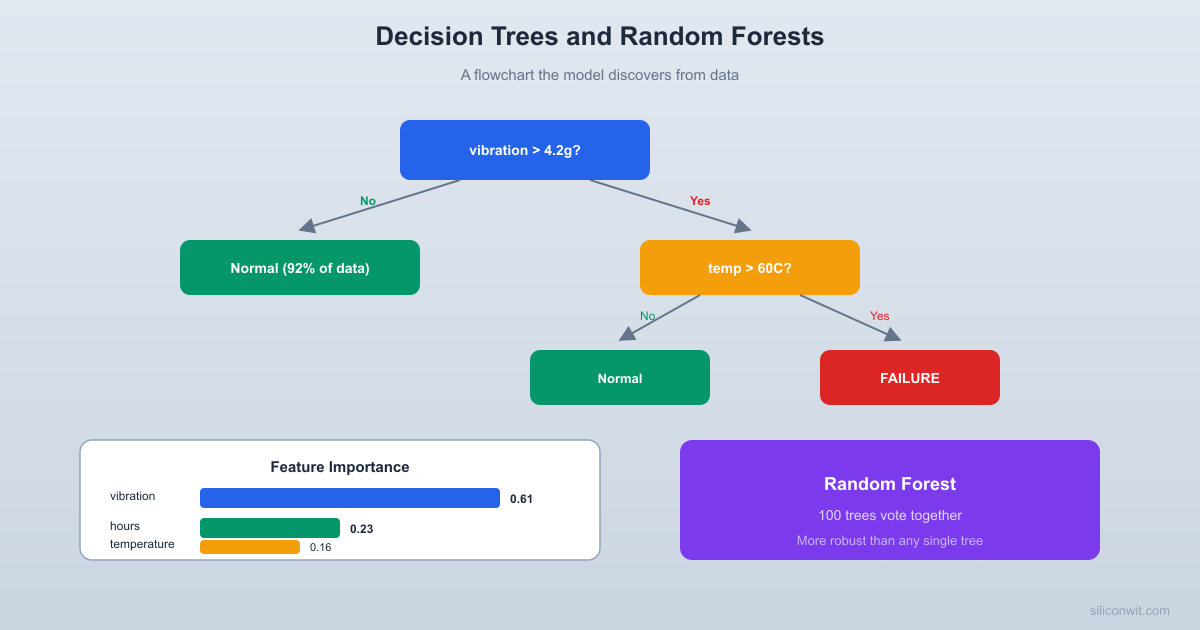
vibration = np.random.exponential(2.0, n_samples) + 1.0
temperature = np.random.normal(65, 12, n_samples)
operating_hours = np.random.uniform(100, 10000, n_samples)
0.3 * (vibration - 3.0) +
0.2 * (temperature - 70) / 10 +
0.1 * (operating_hours - 5000) / 2000 +
0.4 * (vibration - 3.0) * (temperature - 70) / 100
+ np.random.randn(n_samples) * 0.5
threshold_val = np.percentile(failure_score, 85)
labels = (failure_score > threshold_val).astype(int)
X = np.column_stack([vibration, temperature, operating_hours])
X_train, X_test, y_train, y_test = train_test_split(
X, labels, test_size=0.3, random_state=42, stratify=labels
# ── Scale for logistic regression ──
scaler = StandardScaler()
X_train_s = scaler.fit_transform(X_train)
X_test_s = scaler.transform(X_test)
'Logistic Regression': LogisticRegression(random_state=42, max_iter=1000),
'Decision Tree (depth=4)': DecisionTreeClassifier(max_depth=4, random_state=42),
'Decision Tree (depth=10)': DecisionTreeClassifier(max_depth=10, random_state=42),
'Random Forest (100 trees)': RandomForestClassifier(n_estimators=100, max_depth=6, random_state=42),
'Random Forest (500 trees)': RandomForestClassifier(n_estimators=500, max_depth=6, random_state=42),
print(f"{'Model':<30} {'Train Acc':<12} {'Test Acc':<12} {'Test F1':<10} {'CV Mean':<10}")
for name, model in models.items():
# Use scaled data for logistic regression, raw for trees
model.fit(X_train_s, y_train)
train_acc = accuracy_score(y_train, model.predict(X_train_s))
test_acc = accuracy_score(y_test, model.predict(X_test_s))
test_f1 = f1_score(y_test, model.predict(X_test_s))
cv = cross_val_score(model, X_train_s, y_train, cv=5, scoring='accuracy')
model.fit(X_train, y_train)
train_acc = accuracy_score(y_train, model.predict(X_train))
test_acc = accuracy_score(y_test, model.predict(X_test))
test_f1 = f1_score(y_test, model.predict(X_test))
cv = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')
cv_scores_dict[name] = cv
print(f"{name:<30} {train_acc:<12.4f} {test_acc:<12.4f} {test_f1:<10.4f} {cv.mean():<10.4f}")
# ── Visualization: cross-validation scores ──
plt.figure(figsize=(10, 5))
positions = range(len(cv_scores_dict))
plt.boxplot(cv_scores_dict.values(), labels=[n.replace(' (', '\n(') for n in cv_scores_dict.keys()],
boxprops=dict(facecolor='steelblue', alpha=0.5))
plt.title('5-Fold Cross-Validation: Model Comparison')
plt.grid(True, alpha=0.3, axis='y')
plt.savefig('model_comparison.png', dpi=100)
print("\nKey observations:")
print(" 1. Deep trees overfit (high train accuracy, lower test accuracy).")
print(" 2. Random forests are more stable and score higher on test data.")
print(" 3. Logistic regression struggles with the nonlinear decision boundary.")
print(" 4. Cross-validation gives a more reliable estimate than a single test split.")
print("\nPlot saved as model_comparison.png")
Comments