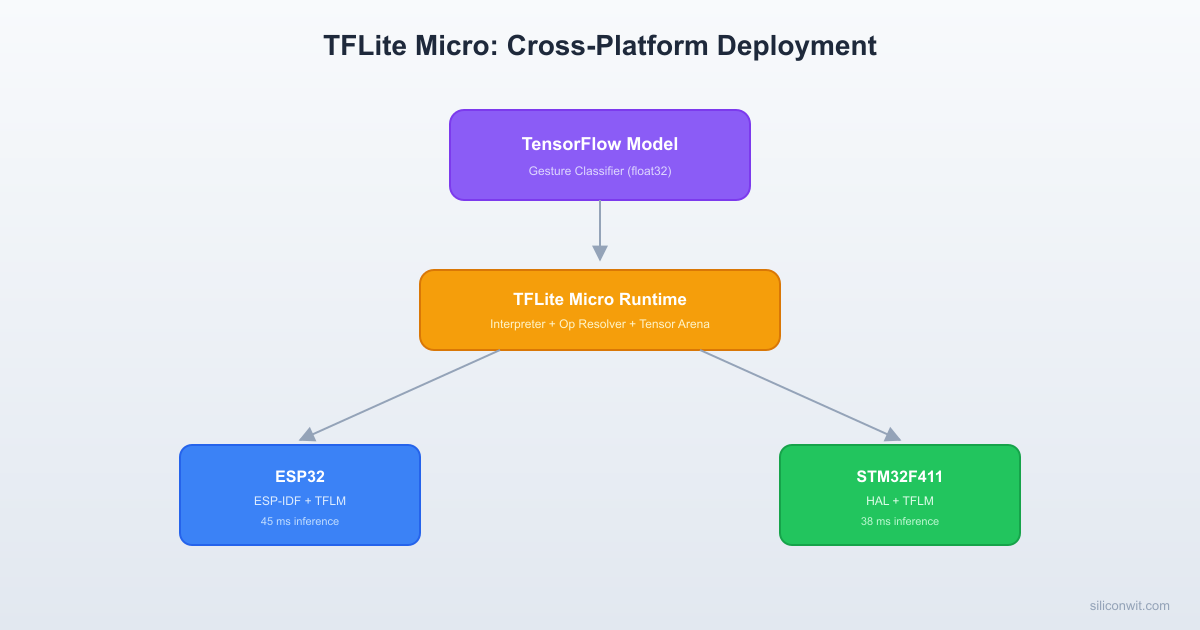
Platforms like Edge Impulse can handle model conversion and deployment automatically, but that convenience comes at the cost of understanding. This lesson takes you inside the TensorFlow Lite for Microcontrollers (TFLM) runtime. You will train a gesture classifier locally in TensorFlow, walk through each stage of model conversion, and deploy the same model on both an ESP32 and an STM32. By porting the model across two different architectures, you will understand exactly how the TFLM interpreter, tensor arena, and op resolver work, and where platform-specific code lives. #TFLiteMicro #ESP32 #STM32
What We Are Building
Cross-Platform Gesture Classifier
A 3-class gesture classifier (wave, punch, flex) that runs on both ESP32 and STM32 using the same TFLite model. An MPU6050 accelerometer captures gesture data at 50 Hz. The firmware collects a 1-second window (50 samples, 3 axes = 150 features), runs inference through the TFLM interpreter, and prints the classified gesture with confidence scores and inference timing.
Project specifications:
Parameter
Value
Gestures
wave, punch, flex
Sensor
MPU6050 (I2C) at 50 Hz
Window
1 second (50 samples x 3 axes = 150 float inputs)
Model
3-layer FC network, int8 quantized
Target 1
ESP32 (Xtensa LX6, 240 MHz, ESP-IDF)
Target 2
STM32F4 (Cortex-M4F, 168 MHz, HAL or Makefile)
TFLM Architecture Deep Dive
The TensorFlow Lite for Microcontrollers runtime has four key components. Understanding each one is essential for debugging deployment issues.
TFLM Runtime Components
──────────────────────────────────────────
Flash (read-only) RAM (tensor arena)
────────────────── ──────────────────
┌──────────────────┐ ┌────────────────┐
│ Model FlatBuffer │ │ Input tensor │
│ (weights + graph)│ │ [150 x int8] │
│ ~8 KB │ ├────────────────┤
└──────────────────┘ │ Layer 1 output │
│ [64 x int8] │
┌──────────────────┐ ├────────────────┤
│ TFLM Interpreter │ │ Layer 2 output │
│ code (~30 KB) │ │ [32 x int8] │
└──────────────────┘ ├────────────────┤
│ Output tensor │
┌──────────────────┐ │ [3 x int8] │
│ Op Resolver │ └────────────────┘
│ (selected ops) │ Total arena: ~4 KB
└──────────────────┘
1. The Model (FlatBuffer)
The .tflite file is a FlatBuffers binary that encodes the model graph (operators and their connections), the quantized weights, tensor shapes and types, and quantization parameters (scale and zero point for each tensor). When embedded as a const unsigned char[] in firmware, the model lives in flash. The interpreter reads it in place; there is no copy to RAM.
Every neural network layer maps to one or more “ops” (operations). The op resolver is a lookup table that connects op names in the FlatBuffer to kernel implementations compiled into the firmware. Using MicroMutableOpResolver<N> instead of AllOpsResolver keeps the binary small. Each unused kernel you exclude saves 1 KB to 10 KB of flash.
If inference fails with “Didn’t find op for builtin opcode”, you forgot to register an op that the model needs. Check the model ops with:
The tensor arena is a single contiguous block of RAM that holds all runtime tensors: input tensor, output tensor, intermediate activation tensors, and scratch buffers for ops that need temporary workspace. The interpreter performs its own memory planning within this arena during AllocateTensors(). There is no malloc after that call.
Sizing the arena: Start large (e.g., 32 KB) and use interpreter.arena_used_bytes() to find the actual usage. Then shrink the arena to the actual usage plus a 10% to 20% margin. An arena that is too small causes AllocateTensors() to fail. An arena that is too large wastes RAM.
The MicroInterpreter ties everything together. It parses the model, allocates tensors in the arena, and on each Invoke() call, executes the ops in topological order. The interpreter is stateless between invocations (given the same input, it produces the same output). This makes it safe to call from a FreeRTOS task without additional synchronization.
Step 1: Collect Gesture Training Data
Use the MPU6050 data collection firmware from Lesson 2. For each gesture, collect at least 50 samples (1-second recordings at 50 Hz).
Gesture Definitions
Gesture
Motion Description
wave
Move hand left-right repeatedly (lateral oscillation)
punch
Thrust hand forward sharply (acceleration spike on one axis)
flex
Rotate wrist upward slowly (gradual tilt change)
Collect data using the serial capture method:
Terminal window
# Collect 50+ recordings per class, each 1 second (50 samples)
The same TFLite model runs on STM32 with minimal changes. The core inference code is identical; only the hardware abstraction layer (I2C, timing, logging) differs.
STM32 Project Structure
Directorygesture_stm32/
Makefile
Directorysrc/
main.cpp
mpu6050.c
mpu6050.h
gesture_model_data.h
gesture_model_data.cc
Directorylib/
Directorytflite-micro/
…
Directorystm32f4xx/
startup_stm32f411xe.s
system_stm32f4xx.c
STM32F411RETx_FLASH.ld
STM32 Inference Code
// src/main.cpp (STM32F4 version)
// Gesture classifier using TFLite Micro on STM32F411
Deploy the same int8 model on both platforms and measure the results.
Inference Time Comparison
Metric
ESP32 (240 MHz Xtensa)
STM32F411 (100 MHz Cortex-M4F)
Model size in flash
~12 KB
~12 KB (identical)
Tensor arena used
~6 KB
~6 KB (identical)
Inference time
0.5 to 2 ms
2 to 8 ms
Total firmware size
~400 KB (with ESP-IDF)
~120 KB (bare metal)
Why the Timing Difference?
The model and runtime are identical. The timing difference comes from three factors:
Clock speed. The ESP32 runs at 240 MHz; the STM32F411 runs at 100 MHz. Higher clock means fewer microseconds per operation.
Cache architecture. The ESP32 has instruction cache for flash-mapped code. The STM32F4 has ART Accelerator (flash prefetch). Both help, but behave differently for the mixed sequential/branching pattern of interpreter execution.
CMSIS-NN acceleration. On Cortex-M4, TFLM can use CMSIS-NN optimized kernels that exploit the DSP instructions (SMLAD, etc.) for int8 dot products. The Xtensa architecture has its own optimizations through Espressif’s esp-nn library. Both provide significant speedups over generic C implementations.
RAM Budget Comparison
RAM Usage
ESP32
STM32F411
Total SRAM
520 KB
128 KB
TFLM arena
6 KB
6 KB
Stack (main task)
8 KB
4 KB
FreeRTOS overhead
~15 KB
0 (bare metal)
Available for application
~490 KB
~118 KB
The ESP32 has abundant RAM for TinyML. The STM32F411 is tighter, but 128 KB is still comfortable for models that need 10 to 20 KB of arena space. Smaller Cortex-M0+ devices (like the RPi Pico with 264 KB, or an STM32L0 with 20 KB) require more careful arena sizing.
Debugging Common Issues
AllocateTensors() fails
The tensor arena is too small. Increase kArenaSize and retry. Use interpreter.arena_used_bytes() after a successful allocation to find the minimum size.
Didn't find op for builtin opcode X
You forgot to register an op. Check which ops the model uses by inspecting it with netron.app (a web-based model visualizer) or by running interpreter.get_output_details() in Python. Add the missing op to the resolver.
Output values are all the same
Check your quantization parameters. If input normalization does not match the training preprocessing (same min, max, scale), the quantized input values will be wrong, and the model output will be garbage. Print the raw quantized input values and verify them against the Python reference.
Inference is too slow
Make sure you are using the optimized kernel implementations (CMSIS-NN for Cortex-M, esp-nn for Xtensa). Check that the build system is compiling with optimization flags (-O2 or -Os). For ESP-IDF, ensure CONFIG_COMPILER_OPTIMIZATION_PERF is enabled in menuconfig.
Model too large for flash
The int8 model should be 3x to 4x smaller than float32. If it is still too large, reduce the number of neurons or layers in the training script. A model with 32 and 16 hidden neurons instead of 64 and 32 cuts the size roughly in half.
Hard fault on STM32
Check stack size. The TFLM interpreter uses significant stack space during AllocateTensors() and Invoke(). Allocate at least 4 KB of stack for the calling thread (or the main stack in bare metal). Also check that the tensor arena is properly aligned (alignas(16)).
Porting Checklist
When moving a TFLM application from one MCU to another, only these pieces change:
Component
Platform-Specific?
Notes
Model (.tflite / C array)
No
Identical binary on all platforms
Op resolver setup
No
Same ops registered everywhere
Tensor arena
No
Same size, same alignment
Interpreter usage
No
Same API calls
I2C / sensor driver
Yes
HAL differs per MCU family
Timing measurement
Yes
esp_timer_get_time() vs HAL_GetTick()
Printf / logging
Yes
ESP_LOGI vs UART printf vs SWO
Build system
Yes
ESP-IDF CMake vs STM32 Makefile vs Arduino
The TFLM code itself is fully portable. This is by design. The “micro” in TFLite Micro means it has no OS dependencies, no dynamic allocation, and no file I/O. You bring the platform layer; TFLM brings the inference engine.
Exercises
Exercise 1: Add RPi Pico
Port the gesture classifier to the RPi Pico W (Cortex-M0+). The Pico lacks an FPU, so int8 quantization is even more important. Compare inference time against the ESP32 and STM32.
Exercise 2: Visualize with Netron
Open your .tflite file in netron.app. Identify each operator, check the tensor shapes, and verify quantization parameters match what the firmware prints.
Exercise 3: AllOpsResolver Comparison
Replace MicroMutableOpResolver<5> with AllOpsResolver. Rebuild and compare the firmware binary size. This shows the cost of unused kernel code.
Exercise 4: Continuous Inference
Implement a sliding window: shift the buffer by 10 samples (200 ms) and re-run inference instead of collecting a full fresh window. Measure how much faster the system responds to gestures.
What Comes Next
You can now train, convert, and deploy TFLite Micro models on multiple platforms. But the models so far have been small, and we accepted the default quantization without questioning it. In Lesson 4 you will take a larger CNN model, apply both post-training quantization and quantization-aware training, and benchmark the accuracy, speed, and size trade-offs in detail.
Comments