In the previous lesson, you fitted polynomials with np.polyfit. That works for one input variable. Real engineering problems have multiple inputs: outdoor temperature, humidity, time of day, building insulation rating, and so on. Linear regression handles this naturally, and scikit-learn makes the pipeline clean and repeatable. In this lesson you will build a complete regression system for predicting indoor temperature from sensor readings, evaluate it with proper metrics, and learn to spot when the model is missing something important. #LinearRegression #ScikitLearn #SensorData
The Problem
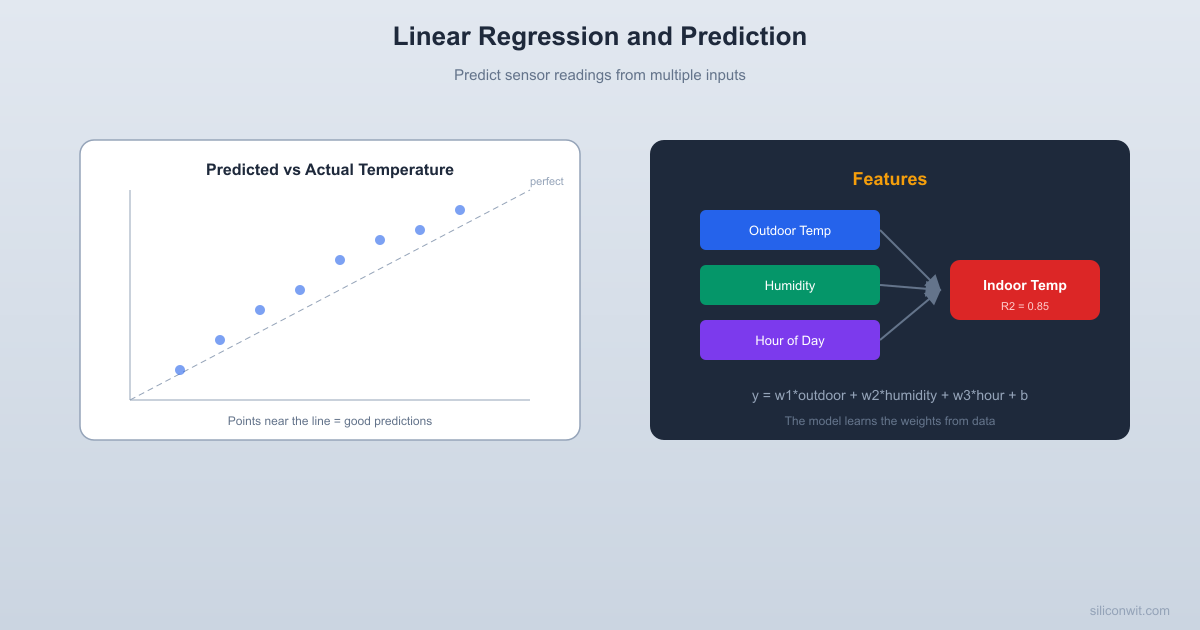
You have a set of environmental sensors measuring outdoor temperature, relative humidity, and time of day. You want to predict the indoor temperature of a building. This is a real problem in building automation, HVAC control, and energy management.
We will generate a synthetic dataset that mimics realistic sensor behavior, then build a model to predict indoor temperature from the measurements.
Step 1: Generate a Realistic Sensor Dataset
Real sensor data is messy. Our synthetic data includes the physical relationships you would expect (indoor temperature tracks outdoor temperature, varies with time of day) plus noise from sensor measurement error.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
n_samples =200
# Feature 1: Outdoor temperature (Celsius), seasonal variation
print("\nPlot saved as sensor_data_exploration.png")
Step 2: Feature Scaling
Linear regression itself does not require feature scaling for correctness. The math works either way. But scaling matters for two practical reasons:
Coefficient interpretation. After scaling, the coefficients tell you which feature has the most influence. Without scaling, a coefficient is entangled with the feature’s units.
Numerical stability. Features with very different scales (humidity in 20 to 95 vs hour in 0 to 23) can cause numerical issues in some algorithms. Gradient descent (covered later) is especially sensitive to this.
scikit-learn’s StandardScaler subtracts the mean and divides by the standard deviation, so every feature ends up with mean 0 and standard deviation 1.
When you scale features, fit the scaler on the training data only. Then use the same scaler to transform the test data. If you fit on the entire dataset, information from the test set leaks into the training process. This is called data leakage and it produces overly optimistic evaluation results.
Watch Out for Multicollinearity
Notice that outdoor temperature and humidity are correlated (our synthetic data uses humidity = 60 - 0.5 * outdoor_temp + noise). When two or more features move together, linear regression cannot cleanly attribute the output to one versus the other. The fit is still accurate, but the individual coefficients become unstable: they can swap signs if you refit on slightly different data, and their magnitudes stop reflecting real physical influence.
In engineering datasets this is the norm, not the exception. Sensors that measure related phenomena (temp and pressure, vibration axes, multiple supply rails) are often highly correlated. Quick diagnostics: compute the correlation matrix with np.corrcoef(X.T), or the Variance Inflation Factor (VIF) from statsmodels. If two features have correlation above about 0.9, consider dropping one, combining them (principal components), or switching to a regularized model like Ridge regression, covered later in the course.
Step 3: Train/Test Split and Model Training
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
axes[1].set_title(f'Error Distribution (MAE = {mean_absolute_error(y_test, y_test_pred):.2f} C)')
axes[1].grid(True,alpha=0.3)
plt.tight_layout()
plt.savefig('regression_evaluation.png',dpi=100)
plt.show()
print("\nPlot saved as regression_evaluation.png")
Step 5: Residual Analysis
Metrics tell you how wrong the model is. Residual analysis tells you why. If the errors show a pattern, the model is missing something systematic.
Residual plots are really a quick check on the three classical linear-regression assumptions:
Linearity. The relationship between features and target is linear. Violation shows up as a curve in the residuals-vs-predicted plot.
Independence and zero mean. Residuals should scatter around zero with no trend across feature values or time. A drift, cycle, or step in residuals-vs-feature means the model is missing a variable or a nonlinear term.
Homoscedasticity. The residual spread should be roughly constant. A fan shape (spread growing with the predicted value) means the error variance depends on the input; predictions on large values are less trustworthy than on small ones.
You do not need to check these formally every time, but you should know what each plot is diagnosing.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
print(f" Mean residual: {residuals.mean():.4f} (should be near 0)")
print(f" Std residual: {residuals.std():.4f}")
print(f" Max |residual|: {np.abs(residuals).max():.4f}")
print()
print("Look at the 'Residuals vs Hour' plot.")
print("If you see a sine-wave pattern, the linear model is missing the daily cycle.")
print("A linear model cannot capture sin(hour) without feature engineering.")
print("Solution: add sin(hour) and cos(hour) as features (next section).")
print("\nPlot saved as residual_analysis.png")
Step 6: Feature Engineering Fixes the Residuals
The residual plot against hour likely shows a sinusoidal pattern. The model is linear, and the daily cycle is a sine wave. A linear model cannot capture a nonlinear relationship unless you give it the right features.
The fix: instead of using hour directly, create sin(2*pi*hour/24) and cos(2*pi*hour/24) as features. This is feature engineering, and it is often more effective than switching to a more complex model.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
print("\nThe engineered features capture the daily cycle that raw hour cannot.")
print("Feature engineering often matters more than the choice of algorithm.")
print("\nPlot saved as feature_engineering_comparison.png")
print("Note: the left subplot has hour (0 to 23) on the x-axis while the right")
print("has sin(2*pi*hour/24). The axes are not directly comparable; what matters")
print("is the residual pattern (left) versus the lack of it (right).")
Connect to Applied Math
Encoding cyclic variables as sine and cosine pairs is the same idea as Fourier decomposition from the Applied Mathematics course. You are projecting a periodic signal onto its fundamental frequency components. The linear model can then learn the amplitude and phase through its coefficients.
The Complete Pipeline
Here is the full pipeline in one script, from data generation to final evaluation.
The ML Regression Pipeline
──────────────────────────────────────────────
Raw Data
│
├── Feature Engineering
│ (encode cyclic variables, add derived features)
│
├── Train/Test Split
│ (70/30 or 80/20, random shuffle)
│
├── Feature Scaling
│ (fit scaler on train ONLY, transform both)
│
├── Model Training
│ (LinearRegression.fit on training data)
│
├── Prediction
│ (model.predict on test data)
│
├── Evaluation
│ (MSE, MAE, R-squared on test set)
│
└── Residual Analysis
(are errors random or patterned?)
If patterned: go back to Feature Engineering
Key Takeaways
Multiple features, same idea. Linear regression with multiple inputs is the same least-squares fitting you know, extended to higher dimensions. scikit-learn handles the linear algebra.
Scale features, fit on training data only. StandardScaler ensures all features contribute proportionally. Fitting on the full dataset is data leakage.
RMSE has the same units as your target. An RMSE of 1.5 C means your predictions are off by about 1.5 degrees on average. MSE squares the units, so interpret RMSE instead.
R-squared tells you the fraction of variance explained. An R-squared of 0.85 means the model captures 85% of the variation in the target. The remaining 15% is noise or missing features.
Residual analysis reveals what the model misses. If residuals show a pattern, the model is systematically wrong. Feature engineering (not a fancier algorithm) is usually the fix.
What is Next
Next, in Classification: Yes or No Decisions, you will move from predicting continuous values to making binary decisions. Instead of “what temperature?” the question becomes “is this sensor board defective?” The math changes only slightly, but the evaluation metrics change completely.
Comments