The term “machine learning” sounds like it requires a PhD and a GPU cluster, which stops many engineers from using it even when a simple model would save them weeks of hand-tuning rules. In reality, you already know the core idea: fit a function to data. You have done it every time you called np.polyfit on a scatter of measurement points. Everything in ML, from logistic regression to deep neural networks, is a variation on that theme. This lesson makes the connection explicit, then shows you where naive curve fitting breaks down (overfitting, underfitting, the bias-variance tradeoff) and what the discipline of ML adds to fix it. #MachineLearning #CurveFitting #BiasVariance
Curve Fitting Is Machine Learning
If you have taken the Applied Mathematics course or any engineering math class, you have fitted curves. You measured some physical quantity, plotted it, and drew a line (or polynomial, or exponential) through the points. The goal was to capture the underlying relationship so you could predict new values.
Machine learning is the same process with three additions:
The computer searches for the best fit automatically (optimization).
You test the fit on data the model has never seen (generalization).
You have formal tools for deciding how complex the model should be (model selection).
plt.plot(x_pred, y_pred,color='tomato',linewidth=2,label=f'Fit: y = {coeffs[0]:.2f}x + {coeffs[1]:.2f}')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Linear Fit with np.polyfit')
plt.legend()
plt.grid(True,alpha=0.3)
plt.tight_layout()
plt.savefig('linear_fit.png',dpi=100)
plt.show()
print("Plot saved as linear_fit.png")
This is the simplest possible ML model. You gave it data, it found the best line, and now it can predict y for any new x. The coefficients are close to the true values (slope 2, intercept 1) but not exact, because of noise. That gap between the fitted values and the true relationship is the first thing ML teaches you to think carefully about.
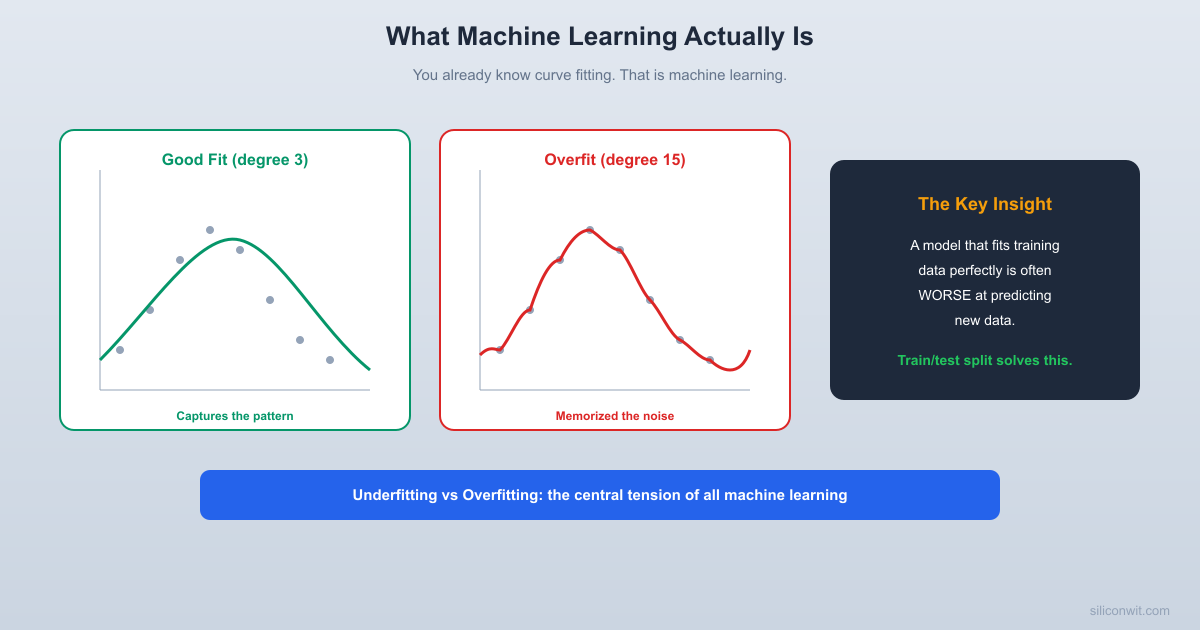
When Fitting Goes Wrong: Overfitting
What happens if you use a more flexible model? The next example switches to a harder underlying relationship, a sine wave with noise, so you can see how model complexity fails. Instead of a straight line, fit a polynomial of degree 15.
print("Notice: degree 15 has the LOWEST training error but the WORST fit.")
print("It passes through every point but wiggles wildly between them.")
print("That is overfitting.")
Look at the degree-15 plot. The curve passes through (or very near) every training point. Its training error is nearly zero. But the curve wiggles wildly between points. If you fed it a new x value between the training points, the prediction would be terrible.
This is overfitting: the model memorized the noise in the training data instead of learning the underlying pattern.
The Train/Test Split: The Fundamental Idea
How do you detect overfitting? You hold out some data that the model never sees during training, then measure how well it predicts that unseen data.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
# Generate 50 data points from a sine curve with noise
Bias is the error from wrong assumptions. A straight line fitted to a sine wave has high bias: no matter how much data you give it, a line can never capture the curve. It underfits.
Variance is the error from sensitivity to fluctuations in the training data. A degree-15 polynomial changes dramatically if you add or remove a single training point. It overfits.
The goal is to find the sweet spot: enough model complexity to capture the real pattern, but not so much that the model memorizes noise.
Connect to Applied Math
If you studied interpolation in the Applied Mathematics course, you saw that high-degree polynomial interpolation can oscillate wildly (Runge’s phenomenon). Overfitting in ML is the same idea: too much flexibility, not enough constraint.
Types of Machine Learning
Not every problem is curve fitting. ML breaks into three families based on the type of feedback the model receives during training.
Supervised Learning
You have input/output pairs: “given this input, the correct output is that.” The model learns the mapping.
Supervised Learning
──────────────────────────────────────
Input (features) Output (label)
────────────────── ──────────────
[temp, humidity] → "rain" or "no rain"
[voltage, current] → "defective" or "good"
[x1, x2, x3] → predicted y value
Regression: output is a continuous number (temperature, price, voltage).
Classification: output is a category (defective/good, spam/not spam, digit 0 through 9).
Most of this course focuses on supervised learning because it is the most immediately useful for engineers.
Unsupervised Learning
You have data but no labels. The model finds structure on its own.
Clustering: group similar data points together (k-means, DBSCAN).
Dimensionality reduction: compress high-dimensional data into fewer dimensions (PCA, t-SNE).
Anomaly detection: find data points that do not fit the normal pattern.
Reinforcement Learning
An agent takes actions in an environment and receives rewards or penalties. Over time, it learns a strategy (policy) that maximizes cumulative reward. Robotics, game playing, and control systems use reinforcement learning. We will not cover it in this course, but the gradient descent techniques you learn here apply to RL as well.
Complete Example: The Overfitting Lab
This script ties everything together. It generates a noisy sine dataset, splits it into train and test sets, fits polynomials of increasing degree, and produces three plots: the fits, the error curves, and a summary table.
Run that script. Study the three fits side by side. Look at the error curve. The pattern is unmistakable: training error always goes down, but test error hits a minimum and then climbs. That U-shaped test error curve is the signature of the bias-variance tradeoff, and recognizing it is the single most important skill in practical machine learning.
Key Takeaways
ML is curve fitting, generalized. You have data, you find a function that describes it. np.polyfit is a machine learning algorithm.
Always evaluate on unseen data. Training error tells you how well the model memorized. Test error tells you how well it generalizes. Only test error matters.
Underfitting means your model is too simple. It cannot capture the real pattern. Increase complexity (more features, higher degree, more flexible model).
Overfitting means your model is too complex. It captures noise along with the signal. Reduce complexity, get more data, or add regularization (covered later in the course).
The bias-variance tradeoff guides every decision. Every model choice, from polynomial degree to neural network depth, trades bias for variance. Your job is to find the sweet spot.
What is Next
Next, in Linear Regression and Prediction, you will move from single-variable polynomial fitting to multi-feature linear regression using scikit-learn. You will build a sensor data pipeline, learn feature scaling, and evaluate your model with proper metrics.
Comments