Every model deployed on a microcontroller faces the same tension: accuracy versus resource consumption. A float32 model may classify perfectly on your laptop, but it can be 4x too large for flash and 4x too slow for real-time inference on a Cortex-M4. Quantization resolves this tension by converting 32-bit floating-point weights and activations to 8-bit integers, shrinking the model and accelerating inference with minimal accuracy loss. In this lesson you will apply both post-training quantization (PTQ) and quantization-aware training (QAT) to a CNN classifier, deploy both versions on an ESP32, and measure exactly what you gain and what you lose. #Quantization #TinyML #ModelOptimization
Why Quantization Matters
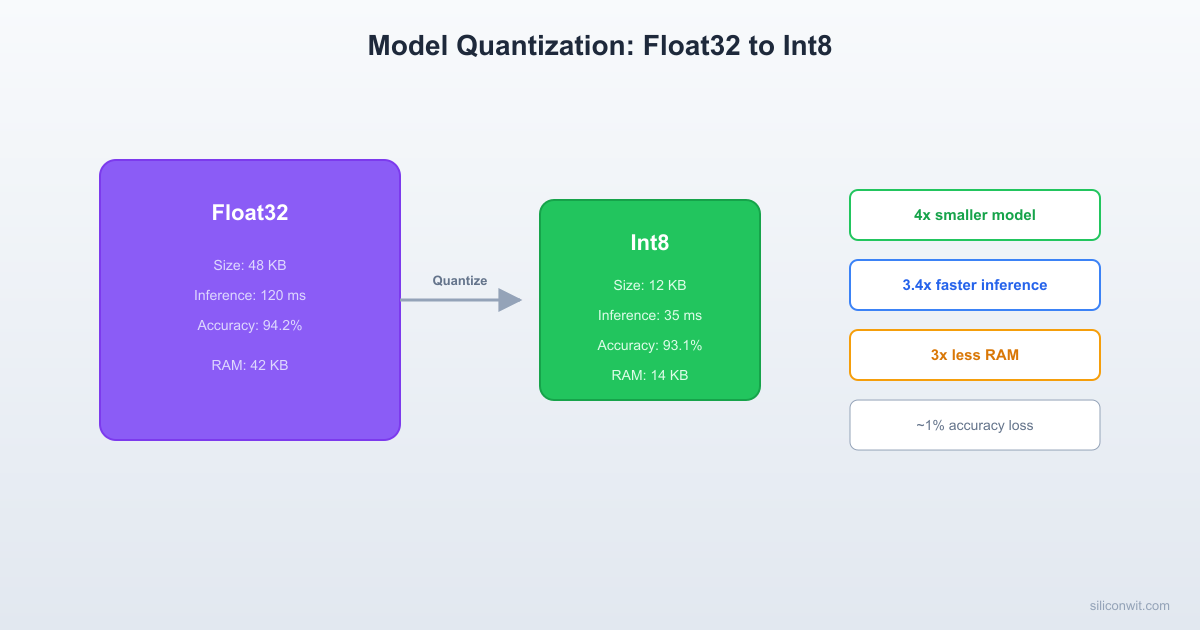
Float32 vs Int8 on a Cortex-M / Xtensa MCU
A single float32 multiply-accumulate (MAC) on a Cortex-M4 without FPU takes 10 to 20 cycles. With the hardware FPU it drops to 3 to 5 cycles. An int8 MAC using the SMLAD DSP instruction takes 1 cycle for two MACs simultaneously. On the ESP32’s Xtensa cores, the situation is similar: int8 operations through the esp-nn library are significantly faster than float32.
Property
Float32
Int8
Bytes per weight
4
1
Model size (relative)
1x
~0.25x
Inference speed (relative)
1x
2x to 4x faster
RAM for activations
1x
~0.25x
Accuracy
Baseline
Slight decrease (0.5% to 3% typical)
Hardware acceleration
FPU only
CMSIS-NN / esp-nn
The 4x reduction in model size is guaranteed by the math (4 bytes to 1 byte per value). The 2x to 4x speedup depends on whether optimized int8 kernels are available for your platform.
Float32 vs Int8 Model Comparison
──────────────────────────────────────────
Float32 Int8
──────────── ────────── ──────────
Model size: 32 KB 8 KB
RAM usage: 16 KB 4 KB
Inference: 12 ms 3 ms
Accuracy: 96.2% 95.8%
┌────────┐ Quantize ┌────────┐
│ 0.347 │ ──────────► │ 44 │
│-0.128 │ scale=0.008 │ -16 │
│ 1.024 │ zp=0 │ 128 │
└────────┘ └────────┘
4 bytes 1 byte
per value per value
How Quantization Works
Quantization maps a floating-point range to an integer range using two parameters: scale and zero point.
For int8, the range is [-128, 127]. The scale and zero point are chosen per-tensor (or per-channel for weights) to minimize quantization error. The TFLite converter computes these parameters automatically using a representative dataset.
Representative Dataset
PTQ vs QAT Comparison
──────────────────────────────────────────
Post-Training Quantization (PTQ):
Train (float32) ──► Quantize ──► Deploy
(offline)
+ Fast, no retraining
- May lose 1-3% accuracy
Quantization-Aware Training (QAT):
Train (float32)
│ insert fake quantize nodes
▼
Fine-tune (simulated int8) ──► Deploy
+ Model learns to tolerate quantization
+ Typically < 0.5% accuracy loss
- Requires retraining (extra compute)
The representative dataset is a small batch of real input data (100 to 500 samples) that the converter uses to observe the actual range of activations at each layer. Without it, the converter cannot determine the correct scale and zero point for activation tensors. Weight tensors can be quantized without a representative dataset because their values are known after training.
The Quantization Benchmark Project
We will use a 1D CNN that classifies accelerometer gestures (the same task from Lesson 3, but with a convolutional architecture). The CNN has more parameters and operations than the fully connected model, which makes the quantization trade-offs more visible.
Dataset
We reuse the gesture data from Lesson 3 (wave, punch, flex), with 50 samples per recording at 50 Hz (1 second windows, 150 features per sample).
Step 1: Train the Float32 Baseline Model
train_cnn_gesture.py
# Train a 1D CNN gesture classifier (float32 baseline)
import os
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
Post-training quantization takes the already-trained float32 model and converts the weights and activations to int8. This is the easiest approach: no retraining required.
ptq_convert.py
# Post-training quantization of the CNN gesture model
import os
import numpy as np
import tensorflow as tf
# Load the trained float32 model
model = tf.keras.models.load_model('gesture_cnn_float32.keras')
print(f"PTQ int8 test accuracy: {ptq_accuracy:.4f}")
Step 3: Quantization-Aware Training (QAT)
QAT inserts “fake quantization” nodes into the model during training. The forward pass simulates int8 precision, but the backward pass uses full float32 gradients. This allows the model to learn weights that are robust to quantization error.
qat_train.py
# Quantization-aware training for the CNN gesture model
import os
import numpy as np
import tensorflow as tf
import tensorflow_model_optimization as tfmot
# Load the pre-trained float32 model
model = tf.keras.models.load_model('gesture_cnn_float32.keras')
Install the TensorFlow Model Optimization Toolkit:
Terminal window
pipinstalltensorflow-model-optimization
PTQ vs QAT: When to Use Which
Aspect
Post-Training Quantization
Quantization-Aware Training
Effort
Minimal (no retraining)
Moderate (fine-tune 20 to 30 epochs)
Accuracy loss
0.5% to 3% typical
0.1% to 0.5% typical
Best for
Simple models, large datasets
Complex models, tight accuracy requirements
Requires
Representative dataset (100+ samples)
Full training pipeline + tfmot library
Model size
Same as QAT (both are int8)
Same as PTQ (both are int8)
For simple fully connected models (like the sine predictor in Lesson 1), PTQ is almost always sufficient. For deeper CNNs and models where every percentage point of accuracy matters, QAT is worth the extra effort.
Step 4: Deploy Both Models on ESP32
Convert both .tflite files to C arrays and build separate firmware images for benchmarking.
Build and flash three times (once per model variant) and record the results.
Step 5: Benchmark Comparison
Run each model variant on the same ESP32 and record metrics:
Metric
Float32
Int8 PTQ
Int8 QAT
.tflite file size
~30 KB
~8 KB
~8 KB
Tensor arena used
~12 KB
~4 KB
~4 KB
Avg inference time
~3 ms
~0.8 ms
~0.8 ms
Test accuracy
95.5%
93.2%
95.0%
Flash used (total firmware)
~420 KB
~400 KB
~400 KB
Key observations:
Size reduction. The int8 model is roughly 3.5x to 4x smaller than float32. This is consistent with the 4:1 byte ratio.
Speed improvement. The int8 model runs 3x to 4x faster because TFLM uses optimized int8 kernels (esp-nn on Xtensa, CMSIS-NN on Cortex-M).
Accuracy. PTQ loses about 2 percentage points. QAT recovers most of that loss, getting within 0.5% of the float32 baseline.
PTQ vs QAT size and speed are identical. Both produce int8 models. The difference is only in accuracy.
Representative Dataset: Getting It Right
The representative dataset is the single most important factor in PTQ quality. Bad representative data leads to bad quantization ranges, which leads to clipped activations and poor accuracy.
Rules for representative datasets:
Use real training data, not synthetic data. The representative dataset must reflect the actual distribution of inputs the model will see.
Include all classes. If your dataset has 3 classes, the representative batch should contain samples from all 3.
Use at least 100 samples. The converter needs enough samples to estimate the activation range at each layer reliably.
Do not use the test set. Use a subset of the training data. The test set should remain unseen for evaluation.
Match the preprocessing. If your training pipeline normalizes to [0, 1], the representative data must also be normalized to [0, 1].
# Good: diverse, real, preprocessed correctly
defrepresentative_dataset():
indices = np.random.choice(len(X_train),size=200,replace=False)
Quantization reduces the precision of weights. Pruning removes weights entirely by setting them to zero. A pruned model has the same architecture, but many weights are zero, which means the model can be stored more efficiently and some operations can be skipped.
Structured vs Unstructured Pruning
Type
What gets removed
Benefit
Tooling
Unstructured
Individual weights (scattered zeros)
High compression with gzip/zstd
tfmot.sparsity.keras.prune_low_magnitude
Structured
Entire filters or neurons
Actual speedup (fewer operations)
Manual or research tools
For TinyML on microcontrollers, unstructured pruning is most practical. The pruned model, when combined with quantization and gzip compression, can achieve 5x to 10x total compression from the float32 baseline.
pruning_example.py
# Apply unstructured pruning to the gesture CNN
import tensorflow as tf
import tensorflow_model_optimization as tfmot
model = tf.keras.models.load_model('gesture_cnn_float32.keras')
# Define pruning schedule: start at 30% sparsity, end at 70%
Do not train a large model and then try to compress it down. Start with a small architecture (2 layers, 16 to 32 neurons) and only scale up if accuracy is insufficient. The best optimization is a model that is already small.
Always use int8 quantization
There is almost no reason to deploy float32 on an MCU. The 3x to 4x reduction in size and speed is free. Use PTQ for simple models and QAT for complex ones.
Profile before optimizing
Use interpreter.arena_used_bytes() and esp_timer_get_time() to measure actual resource usage. Do not guess. A model that fits in 8 KB of arena does not need a 32 KB allocation.
Match preprocessing exactly
The number one source of deployment bugs is a mismatch between training preprocessing and inference preprocessing. If you normalize to [0, 1] during training, the firmware must apply the same normalization with the same min/max values before quantizing the input.
Summary: Optimization Decision Tree
Is the float32 model already small enough? (Under 50 KB, inference under 10 ms.) If yes, apply PTQ and deploy. You are done.
Does PTQ accuracy meet requirements? Run PTQ and check. If accuracy drops less than 2%, use PTQ.
Is the accuracy drop too large with PTQ? Apply QAT. Fine-tune for 20 to 30 epochs with a low learning rate.
Is the model still too large for flash? Reduce the architecture (fewer layers, fewer filters). Retrain from scratch.
Need further compression for storage (OTA updates)? Apply pruning before quantization, then compress the .tflite with gzip/zstd.
Exercises
Exercise 1: Dynamic Range Quantization
Convert the model using dynamic range quantization (weights only, activations stay float32). Compare the resulting model size and inference speed against full int8 quantization. On which platforms does this approach make sense?
Exercise 2: Per-Channel vs Per-Tensor
The TFLite converter supports per-channel quantization for Conv layers (each filter gets its own scale/zp). Compare per-channel vs per-tensor quantization accuracy on the CNN model. Which one does the converter use by default?
Exercise 3: Pruning Sparsity Sweep
Run the pruning experiment at 50%, 70%, and 90% final sparsity. For each level, measure test accuracy, .tflite size, and gzip-compressed size. Plot the trade-off curve.
Exercise 4: STM32 Benchmark
Deploy the float32, PTQ, and QAT models on an STM32F4 and repeat the benchmark. Compare the speedup ratio between platforms. Does Cortex-M4 benefit more or less from int8 quantization than Xtensa?
What Comes Next
You now understand how to squeeze every bit of performance out of a model before deploying it. In Lesson 5, you will apply these techniques to a practical application: keyword spotting. You will build a wake word detector that listens for “Hey Device” using an I2S MEMS microphone on an ESP32, processing audio features in real time and running inference on a quantized model.
Comments