from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
# Regenerate full dataset with features (condensed)
hours = np.arange(n_samples)
daily_cycle = np.sin(2 * np.pi * hours / 24)
vibration = 2.0 + 0.3 * daily_cycle + np.random.normal(0, 0.2, n_samples)
temperature = 50 + 5 * daily_cycle + np.random.normal(0, 1.5, n_samples)
pressure = 5.0 + 0.5 * daily_cycle + np.random.normal(0, 0.15, n_samples)
flow_rate = 100 + 10 * daily_cycle + np.random.normal(0, 3, n_samples)
failure_label = np.zeros(n_samples, dtype=int)
failure_starts = np.sort(np.random.choice(range(200, n_samples - 50), 50, replace=False))
for start in failure_starts:
pre_hours = np.random.randint(24, 48)
ramp_start = max(0, start - pre_hours)
ramp = np.linspace(0, 2.5, start - ramp_start)
vibration[ramp_start:start] += ramp
temperature[ramp_start:start] += ramp * 0.8
label_start = max(0, start - 24)
failure_label[label_start:start + 1] = 1
timestamps = pd.date_range('2025-09-01', periods=n_samples, freq='h')
'vibration': vibration, 'temperature': temperature,
'pressure': pressure, 'flow_rate': flow_rate,
'failure_within_24h': failure_label,
for col in ['vibration', 'temperature', 'pressure', 'flow_rate']:
df[f'{col}_roll6_mean'] = df[col].rolling(6, min_periods=1).mean()
df[f'{col}_roll24_mean'] = df[col].rolling(24, min_periods=1).mean()
df[f'{col}_roll24_std'] = df[col].rolling(24, min_periods=1).std()
df[f'{col}_delta1h'] = df[col].diff(1)
df[f'{col}_delta24h'] = df[col].diff(24)
for col in ['vibration', 'temperature']:
roll168 = df[col].rolling(168, min_periods=1).mean()
df[f'{col}_ratio_6_168'] = df[f'{col}_roll6_mean'] / roll168
df['hour'] = df['timestamp'].dt.hour
df['day_of_week'] = df['timestamp'].dt.dayofweek
# Select features (exclude raw sensor values and timestamp)
feature_cols = [c for c in df.columns
if c not in ['timestamp', 'failure_within_24h',
'vibration', 'temperature', 'pressure', 'flow_rate']]
X = df[feature_cols].values
y = df['failure_within_24h'].values
print(f"Features: {len(feature_cols)}")
print(f"Samples: {len(X)}")
print(f"Class balance: Normal={np.sum(y==0)}, Failure={np.sum(y==1)}")
# Train/test split (time-based: first 80% for training, last 20% for testing)
split_idx = int(0.8 * len(X))
X_train, X_test = X[:split_idx], X[split_idx:]
y_train, y_test = y[:split_idx], y[split_idx:]
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
rf = RandomForestClassifier(
class_weight='balanced', # handle class imbalance
rf.fit(X_train_scaled, y_train)
y_pred = rf.predict(X_test_scaled)
print("PREDICTIVE MAINTENANCE RESULTS")
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names=['Normal', 'Failure']))
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(f" Predicted Normal Predicted Failure")
print(f" Actual Normal: {cm[0][0]:5d} {cm[0][1]:5d}")
print(f" Actual Failure: {cm[1][0]:5d} {cm[1][1]:5d}")
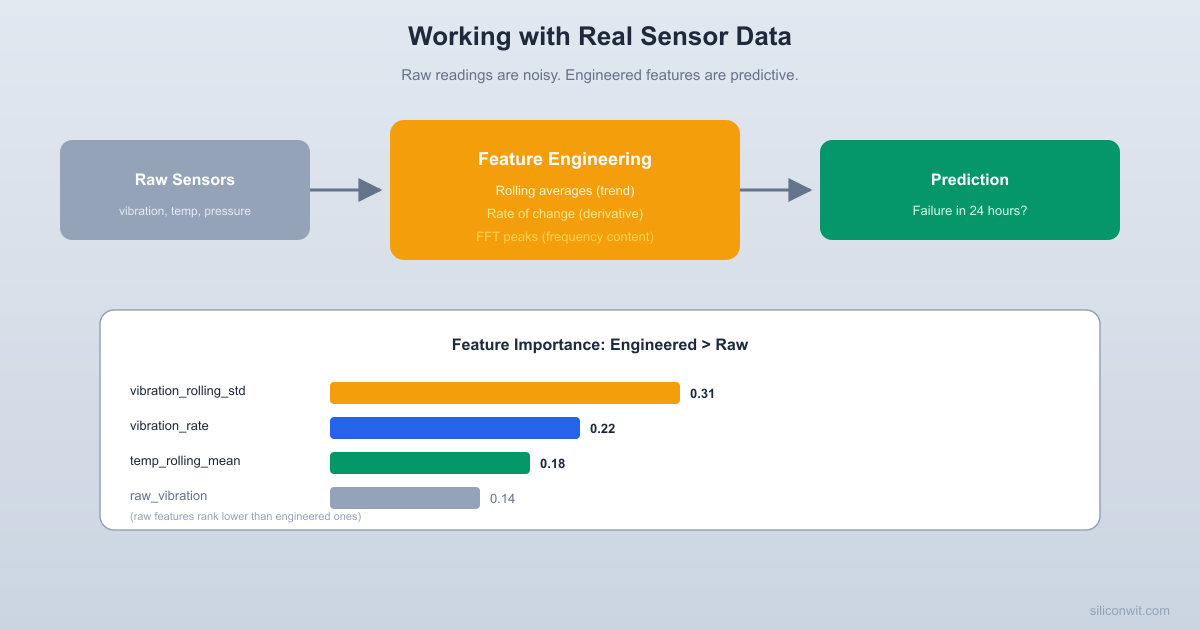
importances = rf.feature_importances_
importance_sorted = sorted(zip(feature_cols, importances),
key=lambda x: x[1], reverse=True)
print("\nTop 10 Most Important Features:")
for name, imp in importance_sorted[:10]:
bar = "#" * int(imp * 200)
print(f" {name:30s} {imp:.4f} {bar}")
Comments